Reactor模型
大量网络框架采用reactor模型进行设计和开发,reactor模式基于事件驱动,特别适合处理海量的I/O事件。
Reactor多线程模型
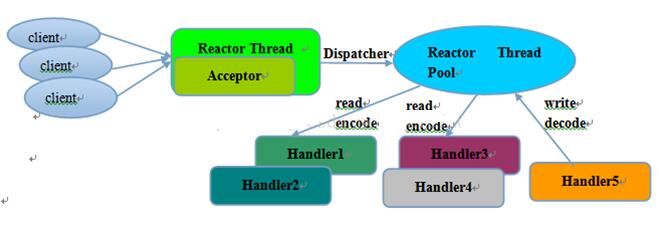
- 有专门的nio线程-acceptor线程用于监听服务端,接收客户端的tcp连接请求
- 网络io操作读写由一个nio线程池负责,包含一个队列和多个可用线程,由这些nio线程负责消息的读取,解码,编码,发送
- 一个nio线程可以同时处理n条链路,反之不可,防止出现并发操作问题
一个nio线程监听和处理客户端连接可能会存在性能问题。
例如百万客户端连接,or 服务端需要对客户端握手进行安全认证,本身非常损耗性能。
为了解决性能问题,出现了主从reactor多线程模型。
Netty中Reactor模型的实现
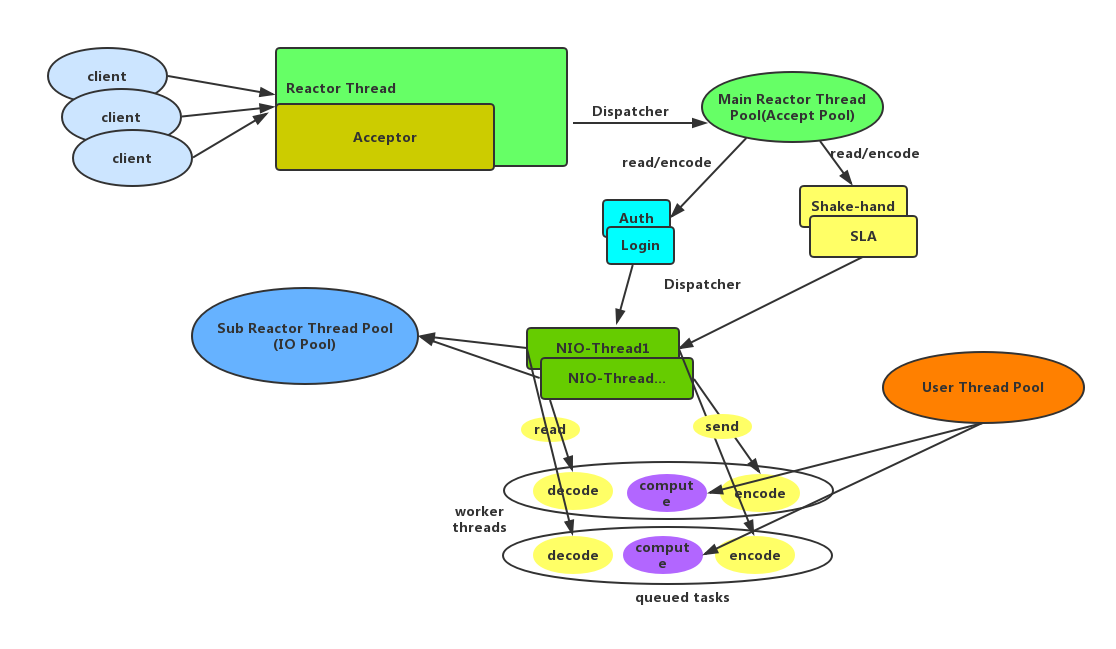
特点
- 服务端接收客户端的连接是一个独立的nio线程池
- accptor线程池仅只用于客户端的登录,握手和安全认证,成功后,将链路注册到subReactor线程池上
- 相比nio创建更少的对象,更小的GC压力;
执行过程
- 从主线程中随机选择一个reactor线程作为accptor线程,用于绑定监听端口,接收客户端连接
- accptor线程接收客户端连接请求后创建新的SocketChannel,将其注册到主线程池的其他reactor线程,其负责接入认证,黑白名单,握手等操作
- 将SocketChannel从主reactor线程摘除,重新注册到sub reactor线程池上,用于读取,解码,编码,发送操作
Netty中几个重要概念及其关系
1.EventLoopGroup
2.EventLoop
3.boss/worker
4.channel
5.event(inbound/outbound)
6.pipeline
7.handler
--------------------------------------------------------------------
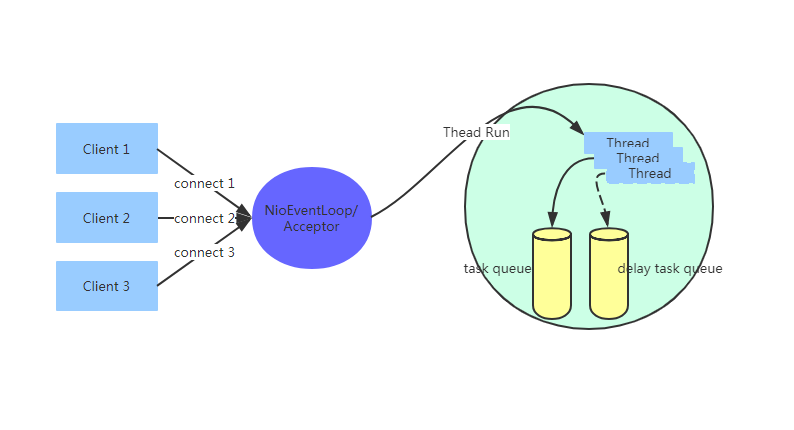
1.EventLoopGroup中包含一组EventLoop
2.EventLoop的大致数据结构是
a.一个任务队列
b.一个延迟任务队列(schedule)
c.EventLoop绑定了一个Thread, 这直接避免了pipeline中的线程竞争
d.每个EventLoop有一个Selector, boss用Selector处理accept, worker用Selector处理read,write等
3.EventLoop执行的任务分为两大类:IO任务和非IO任务.
a.IO任务比如: OP_ACCEPT、OP_CONNECT、OP_READ、OP_WRITE
b.非IO任务比如: bind、channelActive等
4.boss可简单理解为Reactor模式中的mainReactor的角色, worker可简单理解为subReactor的角色
a.boss和worker共用EventLoop的代码逻辑
b.在不bind多端口的情况下bossEventLoopGroup中只需要包含一个EventLoop
c.workerEventLoopGroup中一般包含多个EventLoop
d.netty server启动后会把一个监听套接字ServerSocketChannel注册到bossEventLoop中
e.bossEventLoop一个主要责任就是负责accept连接(channel)然后dispatch到worker
f.worker接到boss转发的channel后负责处理此chanel后续的read,write等event
5.channel分两大类ServerChannel和channel, ServerChannel对应着监听套接字(ServerSocketChannel), channel对应着一个网络连接
6.有两大类event:inbound/outbound(上行/下行)
7.event按照一定顺序在pipeline里面流转, 流转顺序参见下图
8.pipeline是责任链模式的设计,里面有多个handler的,上行事件顺序执行pipeline,下行事件逆序执行pipeline。 同时每个handler节点过滤在pipeline中流转的event, 如果判定需要自己处理这个event,则处理(用户可以在pipeline中添加自己的handler)
--------------------------------------------------------------------
I/O Request
via Channel or
ChannelHandlerContext
|
+---------------------------------------------------+---------------+
| ChannelPipeline | |
| \|/ |
| +---------------------+ +-----------+----------+ |
| | Inbound Handler N | | Outbound Handler 1 | |
| +----------+----------+ +-----------+----------+ |
| /|\ | |
| | \|/ |
| +----------+----------+ +-----------+----------+ |
| | Inbound Handler N-1 | | Outbound Handler 2 | |
| +----------+----------+ +-----------+----------+ |
| /|\ . |
| . . |
| ChannelHandlerContext.fireIN_EVT() ChannelHandlerContext.OUT_EVT()|
| [ method call] [method call] |
| . . |
| . \|/ |
| +----------+----------+ +-----------+----------+ |
| | Inbound Handler 2 | | Outbound Handler M-1 | |
| +----------+----------+ +-----------+----------+ |
| /|\ | |
| | \|/ |
| +----------+----------+ +-----------+----------+ |
| | Inbound Handler 1 | | Outbound Handler M | |
| +----------+----------+ +-----------+----------+ |
| /|\ | |
+---------------+-----------------------------------+---------------+
| \|/
+---------------+-----------------------------------+---------------+
| | | |
| [ Socket.read() ] [ Socket.write() ] |
| |
| Netty Internal I/O Threads (Transport Implementation) |
+-------------------------------------------------------------------+NioEventLoop的设计原理
消息的读取,解码,后续handler的执行,始终由NioEventLoop负责,整个流程不会存在上下文的切换
一个客户端连接只注册到一个NioEventLoop上,避免了多个IO线程并发操作
一个NioEventLoop聚合了一个多路复用器Selector,因此可以处理成千上万的客户端连接
netty通过串行化线程水平并行处理,既能提升了多核并发处理能力,也避免了上下文切换和并发保护带来的额外性能损耗
Code实现:
1 | newchild() |
大致流程: 1.newChild():创建NioEventLoop线程,首先是打开一个selector 2.接着在父类中会构造一个MpscQueue:taskQueue用于外部线程执行(非IO事件)Netty任务的时候,如果判断不是在NioEventLoop对应线程里面执行,非IO事件都是先丢到这个MPSC队列再由worker线程去异步执行,PlatformDependent.newMpscQueue(maxPendingTasks)创建MpscQueue保存异步任务队列; 3.创建一个selector:provider.openSelector()创建selector轮询初始化连接 4.接着DISABLE_KEYSET_OPTIMIZATION是判断是否需要对sun.nio.ch.SelectorImpl中的selectedKeys进行优化, 不做配置的话默认需要优化.
哪些优化呢:
1 | final class SelectedSelectionKeySet extends AbstractSet<SelectionKey> { |
原来SelectorImpl中的selectedKeys和publicSelectedKeys是个HashSet, 新的数据结构是数组, 初始大小1024。
a.避免了HashSet的频繁自动扩容。
b.屏蔽了remove、contains、iterator这些不需要的功能。
c.HashSet用拉链法解决哈希冲突, 也就是说它的数据结构是数组+链表,
而我们又知道, 对于selectedKeys, 最重要的操作是遍历全部元素, 但是数组+链表的数据结构对于cpu的 cache line 来说肯定是不够友好的.如果是直接遍历数组的话, cpu会把数组中相邻的元素一次加载到同一个cache line里面(一个cache line的大小一般是64个字节), 所以遍历数组无疑效率更高.