介绍
Redis 中的字符串是可以修改的字符串,在内存中它是以字节数组的形式存在的。由于Redis对字符串在安全性、效率以及功能方面的要求。自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型, 并将 SDS 用作 Redis 的默认字符串表示。
- 除了用来保存数据库中的字符串值之外, SDS 还被用作缓冲区(buffer)
- AOF 模块中的 AOF 缓冲区, 以及客户端状态中的输入缓冲区, 都是由 SDS 实现的
项目地址:https://github.com/lishq/redis-base-demo
RedisObject
1 | struct SDS<T> { |
上面的 SDS 结构使用了范型 T,为什么不直接用 int 呢,这是因为当字符串比较短时,len 和 capacity 可以使用 byte 和 short 来表示,Redis 为了对内存做极致的优化,不同长度的字符串使用不同的结构体来表示。
### embstr vs raw
Redis 的字符串有两种存储方式,在长度特别短时,使用 emb 形式存储 (embeded),当长度超过 44 时,使用 raw 形式存储。
Redis 对象头结构体
1 | struct RedisObject { |
- 一个 RedisObject 对象头需要占据 16 字节的存储空间。
SDS结构体
1 | struct SDS { |
- 在字符串比较小时,SDS 对象头的大小是capacity+3,至少是 3。意味着分配一个字符串的最小空间占用为 19 字节 (16+3)。
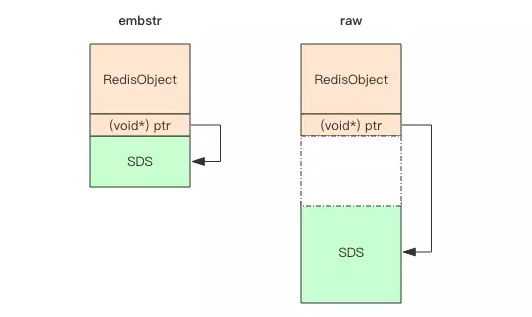
embstr将RedisObject对象头和sds连续存储,只需要一次malloc,占用内存更少。但是每次改变需要重新分配内存。
raw需要两次malloc,两个对象头在内存地址不连续。
因为jemalloc/tcmalloc 等分配内存的单位是2的指数。如果长度超过64bytes,redis认为是大字符串。不再使用embstr存储,改用raw形式。
看上面这张图可以算出,留给 content 的长度最多只有 45(64-19) 字节了。字符串又是以\0结尾,之所以多出这样一个字节,是为了便于直接使用 glibc 的字符串处理函数,所以 embstr 最大能容纳的字符串长度就是 44。
扩容策略
字符串在长度小于 1M 之前,扩容空间采用加倍策略,也就是保留 100% 的冗余空间。当长度超过 1M 之后,为了避免加倍后的冗余空间过大而导致浪费,每次扩容只会多分配 1M 大小的冗余空间。
Redis 规定字符串的长度不得超过 512M 字节。创建字符串时 len 和 capacity 一样长,不会多分配冗余空间,这是因为绝大多数场景下我们不会使用 append 操作来修改字符串。
C字符串和 SDS 之间的区别
- 获取字符串长度的复杂度由O(N)降为O(1) 。
- API 是安全的,不会造成缓冲区溢出。
- 修改字符串长度 N 次最多需要执行 N 次内存重分配。
- 可以保存文本或者二进制数据。
- 可以使用一部分 <string.h> 库中的函数。