介绍
Redis 为了节约内存空间使用,zset 和 hash 容器对象在元素个数较少的时候,采用压缩列表 (ziplist) 进行存储。压缩列表是一块连续的内存空间,元素之间紧挨着存储,没有任何冗余空隙。
项目地址:https://github.com/lishq/redis-base-demo
ziplist
1 | struct ziplist<T> { |
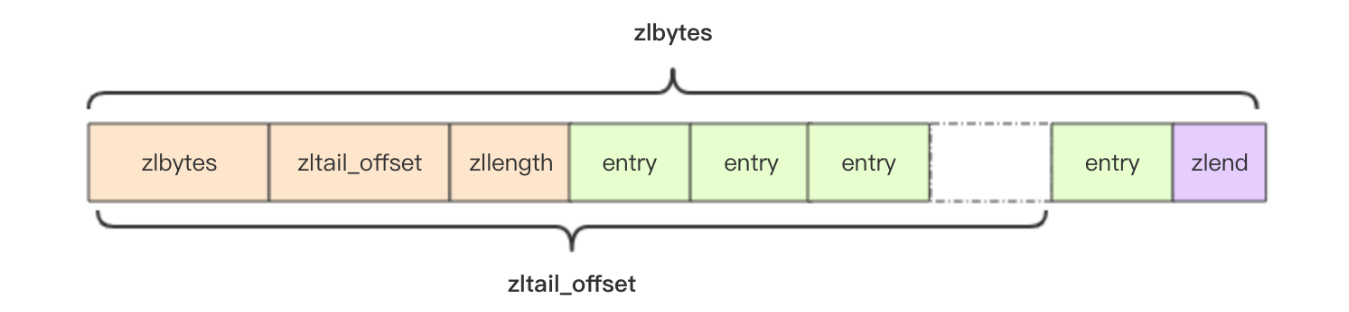
压缩列表为了支持双向遍历,所以才会有 ztail_offset 这个字段,用来快速定位到最后一个元素,然后倒着遍历。
entry 块随着容纳的元素类型不同,也会有不一样的结构。
1 | struct entry { |
- 它的 prevlen 字段表示前一个 entry 的字节长度,当压缩列表倒着遍历时,需要通过这个字段来快速定位到下一个元素的位置。
- 它是一个变长的整数,如果entry.content小于254字节,prevlen是1个字节,内容大于254则prevlen是5个字节。所以list中内容变化可能导致级联更新的问题。
- 当字符串长度比较长的时候,5 个字节只占用不到(5/(254+5))<2%的空间。
增加元素
因为 ziplist 都是紧凑存储,没有冗余空间 (对比一下 Redis 的字符串结构)。意味着插入一个新的元素就需要调用 realloc 扩展内存。取决于内存分配器算法和当前的 ziplist 内存大小,realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,也可能在原有的地址上进行扩展,这时就不需要进行旧内容的内存拷贝。
如果 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
连锁更新
- 如果 ziplist 里面每个 entry 恰好都存储了 253 字节的内容,那么第一个 entry 内容的修改就会导致后续所有 entry 的级联更新,这就是一个比较耗费计算资源的操作。
- 如果 ziplist 里面每个 entry 恰好都存储了 253 字节的内容,其中big 节点的长度大于等于 254 字节, 而 small 节点的长度小于 254 字节, 那么当我们将 small 节点从压缩列表中删除之后, 也会导致后续所有 entry 的级联更新。
IntSet 小整数集合
当 set 集合容纳的元素都是整数并且元素个数较小时,Redis 会使用 intset 来存储结合元素。intset 是紧凑的数组结构,同时支持 16 位、32 位和 64 位整数。
1 | struct intset<T> { |

1 | 127.0.0.1:6379> sadd lishq:test 1 2 3 |
观察 debug object 的输出字段 encoding 的值,可以发现当 set 里面放进去了非整数值时,存储形式立即从 intset 转变成了 hash 结构。
总结
- 压缩列表是一种为节约内存而开发的顺序型数据结构。
- 压缩列表被用作列表键和哈希键的底层实现之一。
- 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
- 添加新节点到压缩列表, 或者从压缩列表中删除节点, 可能会引发连锁更新操作, 但这种操作出现的几率并不高。